
Meeting With Yves Rosseel
Following some mail exchange with Yves Rosseel about the simulation work I have been doing on SEMs, finding out that we both live in the same city we organized a small chat at a nearby café. Yves Rosseel is the creator and maintainer of the lavaan package in R, you can check out his recent talk at the useR! Conference last year on models, softwares and stories around SEMs. Yves Rosseel comes from a psychological background, he has been working on neuro-imaging but has moved now more towards methods development and education. So this means that while developing lavaan he had in mind typical applications for psychological research.
Below is my recollection of our discussion any mistakes or imprecision is on me.
- It is all about latent variable: latent variables are what makes SEMs very powerful. The basic ideas behind latent variables is that there is some unmeasured process out there, say Diversity, and you collected a bunch of indicator variables (like species richness, evenness …) that all represent some aspects of the process. Latent variables is then extracting this shared information between the indicators and throwing out all the rest. We can represent this via a Venn diagram:
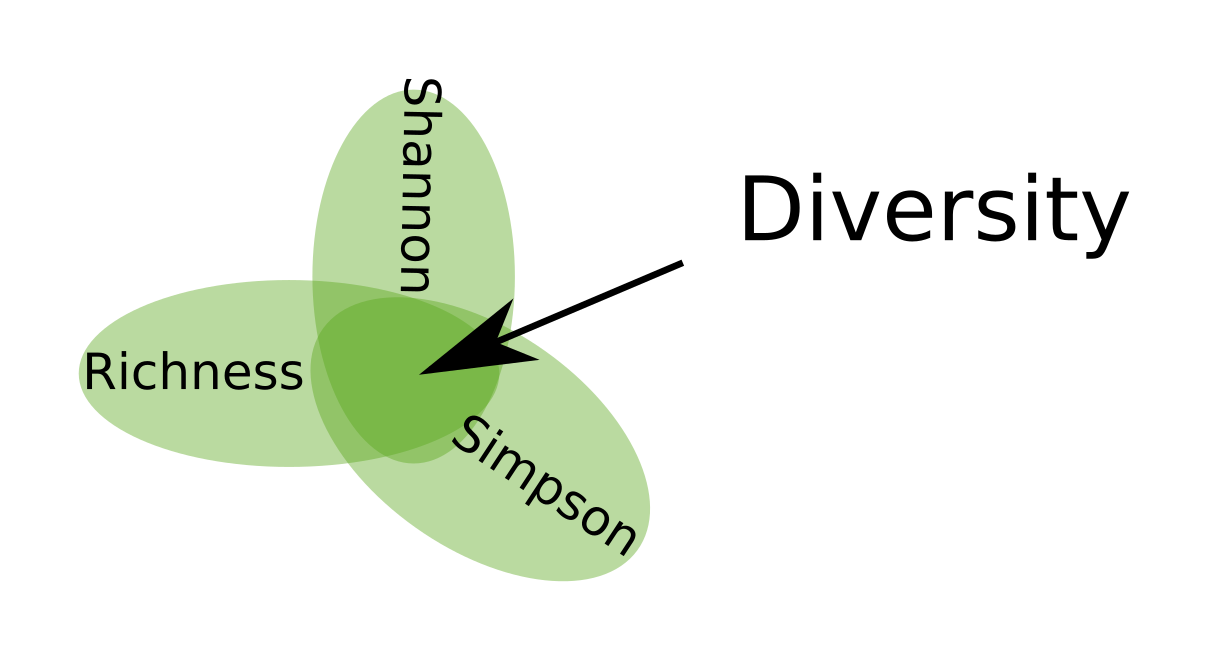 An example of a latent variable: diversity, as measured by three indicators: species richness, shannon and simspon diversity. The darker area represent the shared information between the three variables which is the part that is of interest in SEMs
An example of a latent variable: diversity, as measured by three indicators: species richness, shannon and simspon diversity. The darker area represent the shared information between the three variables which is the part that is of interest in SEMs
Using latent variables have several advantages such as: (i) measurement errors is taken into account and (ii) different aspects of a process can be combined. That said latent variables were developed for typical questionnaire data where the answer from each question can inform about some process like Motivation or Depression. For ecologists, latent variables may be a bit more tricky especially because observed variables that we think stem from the same process might be uncorrelated, for whatever reasons, and this might lead to poor estimation. Yves Rosseel is not that comfortable calling SEMs without latent variables SEMs, for him such models are “just” a list of individual regression without the unique SEM flair.
-
A library of latent variable construct: some psychologists have spent their whole career developing indicators that are good measures of some unmeasured process. Building up so-called construct, a combination of a latent variable (what is unmeasured) and its indicators. This means that other psychologist can just take these off-the-shelfs constructs and use them in their research. Of course there is still some checking involved to see if the construct show good behavior in the collected dataset. But it means that you can design your data sampling by finding out what you want to relate and picking up the relevant indicators to collect. I dream that one day we’ll have similar libraries in ecology for concepts like (Multi)diversity or stability. Maybe this is something that the people involved with the Essential Biodiversity Variables are trying to achieve …
-
Causality is a nasty things: as ecologists we come to SEMs mainly to unravel the mechanisms behind our messy patterns. Apparently psychologists tend to ignore causality when deriving their SEMs. They rather go for a way more pragmatic approach, for instance say you are interested in developing and testing a new educational program for improving the reading abilities of school kids. You may manipulate two different potential drivers of reading abilities: motivation and reading frequency. You collect your data and you fit a model such as presented in the figure below.
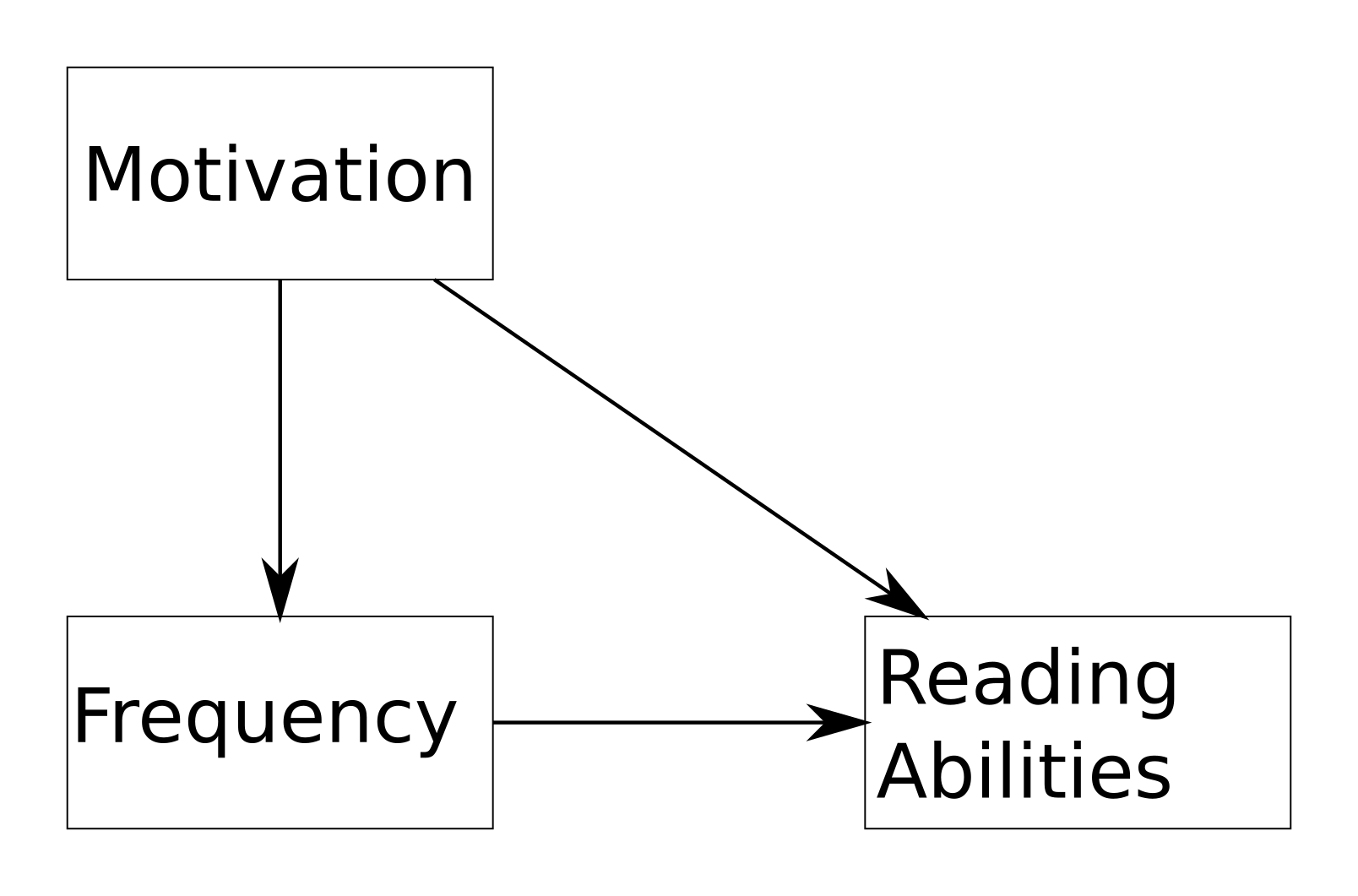 A programm officer asks you if reading motivation or reading frequency should be targeted when designing a new educational program aiming at increasing reading abilities. The following model would be fitted to data.
A programm officer asks you if reading motivation or reading frequency should be targeted when designing a new educational program aiming at increasing reading abilities. The following model would be fitted to data.
Of course the true causal structure of such a system might be more complex, with reading abilities feeding back on motivation and other factors coming into play. The main idea there is rather than trying to get the mechanistic structure right, draw the arrows in the direction that fits your (applied) needs. An example in ecological settings might be for restoration projects, with the end goal being plant diversity affected by different drivers that can be manipulated such as phosphorus concentration and mowing frequency. Bottom-line is (according to Yves Rosseel), SEMs are not a magical solution to understand cause and effects from observational data. Of course there is some debate on that, see for instance this paper by Pearl an ardent defender of the causal nature of SEMs, or this blog post on dynamic ecology which is both a great reference source and cater(ed) some nice discussions. You can also read my attempts at discussing causes and mechanisms.
-
If you forgo latent variable, better build saturated models: in the simple path analysis case (SEMs without latent variable and with no recursion), it is better to build and explore saturated models to avoid distortion during estimation. Distortion, in this case, means that you increase the bias of your coefficient by dropping some potentially important relations. Saturated models are models with as many parameters being estimated as there are degrees of freedom, so basically fitting saturated models leads to 0 degrees of freedom which means that you cannot compare between models or assess model fit via classical chi-square tests. Two issues here: (i) for any given set of variables there may be more than one saturated model possible, we have no formal way to compare them, (ii) the issue of distortion during parameter estimation is certainly an issue for global estimation via lavaan, but I am not sure that it is also present when using local estimation like via piecewiseSEM
-
Smaller things:
-
lavPredict(): the function lavPredict does not report model fitted values for the response variables. It is rather the factor loadings of the latent variables. In other words, lavPredict will report for each latent variables the score that your observations get. So if you had a latent variable, say diversity, lavPredict will give you predicted diversity scores for each data points. Note that there is no (frequentist) way to propagate the uncertainty in SEMs in order to get new predicted responses. I would assume that a Bayesian approach would solve that.
-
future enhancement of lavaan: support for non-parametric parameter estimation which would make it possible to work with non-linear responses, also support for categorical data
-
rise and fall of SEMs: it is also very interesting for Yves Rosseel that SEMs are being more and more hyped in ecology, in psychology this is identified as a method of the old time, and now researcher actually name it differently (dynamic causal models) to make it look more sexy, some statistical machismo there (?). More generally (and maybe unrelated), I have the feeling that science is turning more and more towards a communication battleground, where the way you communicate is more important than what you do. Maybe this is because I am slowly starting to see behind the grant proposal curtain and it had always been that way …
-
To sum up Yves Rosseel main points: SEMs are cool, but not for the reasons that ecologists usually attribute to them.

Leave a Comment